از چالشهای مهندسی داده: Batch یا Stream?
یه جایی تو مسیر هر data engineerی هست که هیجان ساختن pipelineها یهدفعه با یه سؤال سخت و ساکت روبهرو میشه:
این باید batch باشه یا real-time؟
ظاهراً سؤال فنیه، ولی در واقع یه سؤال فلسفیه. پشتش یه دغدغهی عمیقتره:
داریم چی رو بهینه میکنیم؟ تازگی، سادگی، یا پایداری؟
چون نمیتونی هر سه رو با هم داشته باشی.
بیاین این دوگانگی رو باز کنیم — نه با حرف زدن از ابزارها، بلکه با بررسی مفاهیمی که هر سیستم دادهای رو شکل میدن.
سه مفهوم اصلی پشت هر تصمیم دادهای
هر data pipeline تو فضایی زندگی میکنه که بین سه ویژگی درگیر تعادل برقرار میکنه:
- Latency — سرعت در دسترس شدن داده
- Complexity — سختی ساخت و نگهداری
- Consistency — درستی و تکرارپذیری نتایج
مشکل چیه؟ شما نمیتونی هر سه مورد رو همزمان بهینه کنی
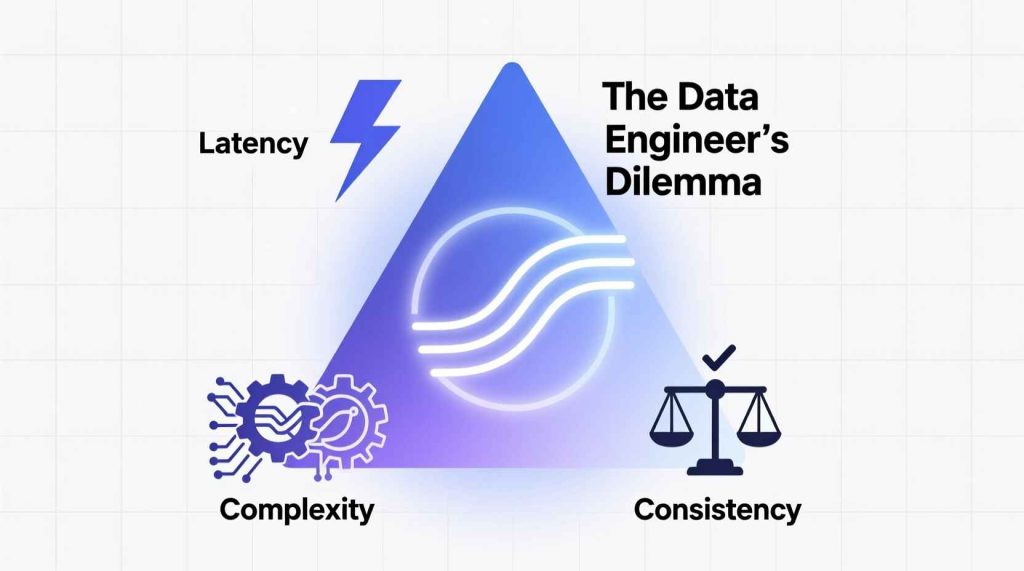
اگه بخوای latency پایین و consistency بالا داشته باشی، هزینهش میشه complexity.
اگه simplicity و correctness رو بخوای، باید از سرعت بگذری.
این همون دوراهی اصلی data engineerهاست.
چالش واقعی انتخاب ابزار نیست — انتخاب راهیه که قراره طی کنی.
Batch، Stream و نقطهی بینابین
یه لحظه ابزارها رو فراموش کن. بذار ببینیم خودِ داده چطور رفتار میکنه.
Batch
Batch فرض میگیره دنیا میتونه یه کم مکث کنه.
میذاری داده برسه، یه snapshot میگیری، پردازش میکنی و خروجیای میدی که کامل و قابل حسابرسیه.
مثل روزنامهای که هر صبح چاپ میشه — چیزی که امروز چاپ شد، تا فردا تغییری نمیکنه.
Batchها فهمیدنشون راحتتره چون زمان مرز داره.
اگه خراب بشن، با صدای بلند میمیرن، میتونی دوباره اجراشون کنی، و خروجیهاشون پایدارن.
ولی همیشه یه قدم از واقعیت عقبن.
Stream
Streaming برعکس، فرض میگیره دنیا هیچوقت نمیایسته.
داده مدام میریزه و تو همون لحظه باید پردازشش کنی — بدون اینکه منتظر کامل شدنش بمونی.
مثل پخش زندهی خبر؛ آنی میفهمی چی شده، ولی ممکنه بعداً جزئیات عوض بشن.
مزیتش تازگیه، ولی هزینهش عدم قطعیت.
تو streaming باید با eventهای دیررس، state متغیر و حقیقت در حال حرکت کنار بیای.
نمیتونی فقط rerun کنی؛ باید بلد باشی با خود زمان کار کنی.
Hybrid
Hybridها میخوان بهترین هر دو دنیا رو داشته باشن.
real-time نتیجه میدن، ولی بعداً برای دقت بیشتر دوباره پردازش یا sync میکنن.
مثل نوار خبری زندهای که شب به یه گزارش رسمی و درست تبدیل میشه.
بهش میگن convergent pipeline — یعنی داده اولش پر سر و صداست، ولی با زمان پایدار میشه.
یه مصالحهی بالغ: اول سریع، بعد درست.
ابعاد تصمیمگیری و trade-offها
وقتی بین batch، stream و hybrid تصمیم میگیری، فقط “سرعت” مهم نیست.
یه سری ابعاد عمیقتر وجود داره که واقعاً تعیینکنندهن.
Latency در مقابل Consistency
Batch خروجی کامل و قابل اطمینان میده — دقیقاً میدونی کدوم داده داخلش بوده.
Stream برعکس با واقعیت ناقص سروکار داره — داده ممکنه دیر برسه، دوبار بیاد یا ترتیبش عوض بشه.
قاعدهی کلی:
اگه منطق downstreamت به یه تصویر نهایی و غیرقابل تغییر از زمان نیاز داره، batch بهترین دوسته.
اگه با حقیقت مرحلهبهمرحله کنار میای، برو سمت stream.
Complexity در مقابل Maintainability
سیستمهای stream از نظر مفهومی پیچیدهان، چون زمان هیچوقت تموم نمیشه.
باید checkpoint، state management، event-time و کلی چیز دیگه رو هندل کنی.
در حالی که batch یه دنیای مستقل داره
State و Reprocessing
توی batch، خود داده همون stateه.
ولی تو stream باید state رو نگه داری — چیزایی مثل مجموع تا این لحظه یا نتایج تجمعی.
یه مثال با Python:
# Batch
data = load_file("sales_2025_10_28.csv")
total_sales = data.groupby("region")["amount"].sum()
store(total_sales, "daily_summary.csv")
# Stream
state = defaultdict(float)
for event in consume_stream("sales_topic"):
state[event["region"]] += event["amount"]
if should_emit_update():
emit("sales_live_summary", dict(state))
توی batch نتیجه نهایی و تمیزه.
توی stream، نتیجه یه جریان مداومه — داستان هیچوقت تموم نمیشه.
زمان یه طیفه، نه یه دکمه
ما معمولاً دربارهی batch و streaming مثل دو گزینهی صفر و یکی حرف میزنیم.
ولی در واقعیت، “timeliness” یه طیفه.
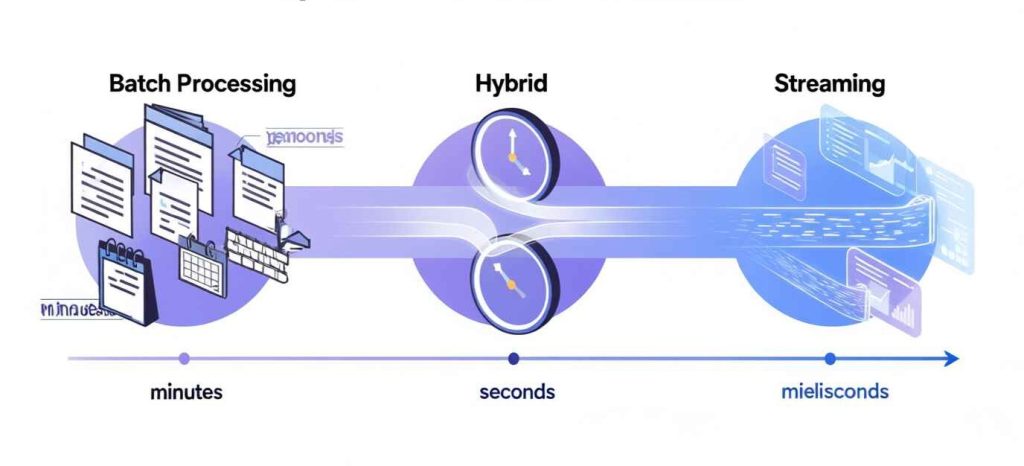
بعضی سیستمها هفتهای یه بار aggregate میخوان، بعضیا هر دقیقه یا هر ثانیه.
موضوع “real-time بودن” نیست — موضوع “right-time بودن”ه.
از خودت بپرس:
- مصرفکنندهت تا چند ثانیه یا دقیقه میتونه صبر کنه تا داده بیارزش نشه؟
- هزینهی دادهی کهنه چقدره در مقابل هزینهی پیچیدگی عملیاتی؟
گاهی refresh ساعتی، بهاندازهی کافی real-time به حساب میاد —
و کاملاً هم قابل قبوله.
یه چارچوب برای انتخاب
قبل از اینکه وارد بحث معماری بشی، این پنج سؤال مفهومی رو از خودت بپرس:
- ماهیت eventها — گسستهان (مثل تراکنشها) یا پیوسته (مثل سنسورها)؟
- تحمل در برابر delay — بین رخ دادن و تحلیل چقدر فاصله مجازه؟
- تصحیح خطا — لازمه بعداً دادههای گذشته رو دوباره بنویسی یا درست کنی؟
- توان عملیاتی تیم — میتونی سیستم ۲۴/۷ با alert و incident داشته باشی؟
- چرخهی عمر حقیقت — داده بعد یه مدت ثابت میشه یا همیشه در حال تغییره؟
اکثر وقتا جواب به سمت hybrid میره — لایهی سریع برای دید اولیه، لایهی کند برای واقعیت نهایی.
Convergent Pipelines: جایی که آینده داره میره
سیستمهای مدرن دارن هر دو دنیا رو با هم ترکیب میکنن.
eventها رو نزدیک real-time پردازش میکنن، insightهای سریع میدن و بعداً backfill برای صحت انجام میدن.
این روش خیلی با واقعیت کسبوکار همراستاست — چون اطلاعات هم با زمان پختهتر میشن.
دادهای که امروز برای مانیتورینگ “کافیه”، فردا میتونه “حقیقت نهایی” بشه.
میتونی ذهنتو اینطوری بچینی:
- Immediate layer: تازه و تقریبی
- Correction layer: تأییدشده و پایدار
- Historical layer: نهایی و بهینه برای تحلیل
نتیجه سیستمیه که با زمان تکامل پیدا میکنه — درست مثل خود دانش.
فراتر از تکنولوژی: بخش انسانی ماجرا
انتخاب بین batch و stream فقط تصمیم فنی نیست.
به تیم، فرهنگ و اولویتهات هم بستگی داره.
Batch برای تیمهایی که کنترل، سادگی و auditability براشون مهمه عالیه.
Streaming برای تیمهاییه که بلوغ عملیاتی دارن و از تغییر مداوم نمیترسن.
Hybrid هم به ارتباط قوی بین تیمهای data، infra و بیزنس نیاز داره —
چون توش “حقیقت” یه فراینده، نه یه محصول نهایی.
در واقع، معماری دادهات بازتاب ارزشهای سازمانته. و یادتون باشه یهو قرار نیست یک چیزی رو پیاده کنیم که کسی برنامهای برای یادگیری نداره و توی تیم فقط یک نفر توان انجامش رو داشته باشه.
جمعبندی
در نهایت هیچ جواب واحدی وجود نداره.
هر pipeline یه داستانه — دربارهی سازندهش، اولویتهاش و ترسهاش.
Batch، stream یا hybrid بودن یه هویت فنی نیست.
یه فلسفهی طراحیه.
و بهترین مهندسها اونایین که فقط “انتخاب درست” نمیکنن —
بلکه میفهمن چرا انتخابشون معنی داره.





