ساخت دیتا پایپلاین مقیاسپذیر
از اسکریپتهای ساده تا پایپلاینهای پیشرفته: مسیر من به عنوان مهندس داده
سفر من در حوزه مهندسی داده با اسکریپتهای ساده پایتون برای یک آژانس مسافرتی آغاز شد و در حال حاضر مشغول طراحی معماری پروژههای بزرگ دیتایی هستم. در این پست، تجربیاتم در این مسیر رو شرح میدم و میبینیم که چطور پایپلاینهای داده با رشد نیازهای کسبوکار تکامل پیدا میکنند.
برای مطالعه درباره ابزارهای ضروری مهندسی داده، پست قبلی رو بررسی کنید: ابزارهای ضروری برای مهندسی داده
مرحله ۱: شروع ساده – اسکریپتهای پایتون و کرون جابها
زمانی که برای اولین بار روی پایپلاینهای داده کار کردم، نیازها بسیار ساده بودند. وظیفه داشتم یک فرآیند کوچک جمعآوری داده را برای یک آژانس مسافرتی خودکار کنم. برای این کار لازم بود دادههای بلیتهای فروختهشده را از یک API دریافت کرده و در یک پایگاه داده رابطهای برای گزارشگیری و داشبوردهای هوش تجاری ذخیره کنم.
راهحل ساده بود. من یک اسکریپت پایتون نوشتم که:
- دادهها با استفاده از requests پایتون از API دریافت میشد.
- به کمک کتابخانه pandas عملیات پاکسازی و تبدیل روی دادهها انجام میشد.
- دادههای ساختاریافته در پایگاه داده PostgreSQL ذخیره میشدند.
- از کرون جابها برای زمانبندی اجرای اسکریپت هر چند ساعت یکبار استفاده میشد.
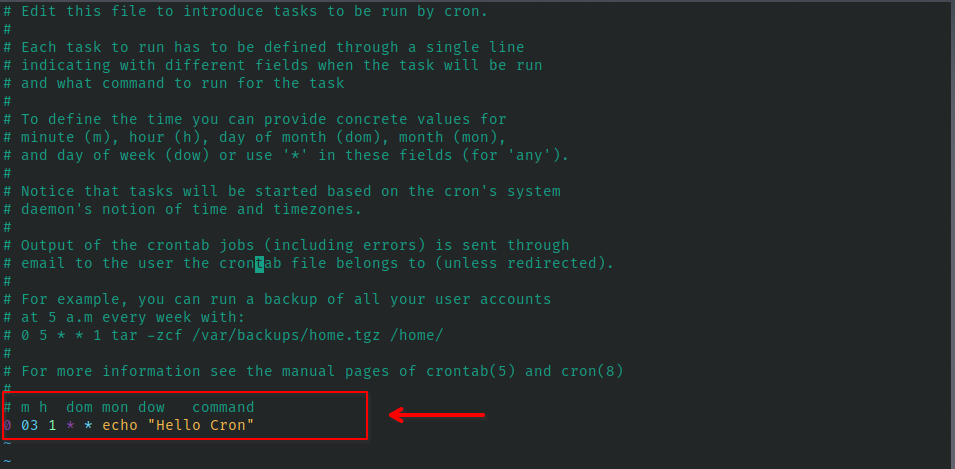
در ابتدا، مقیاس مسئله را ارزیابی کردم. به دلیل سادگی و مقیاس کوچک، تصمیم گرفتم از کرون جاب استفاده کنم که یکی از ابزارهای کاربردی لینوکس هست. این ابزار ساده به شما اجازه میده دستورات را در زمانهای مشخص اجرا کنید، بدون توجه به اینکه زبان آن پایتون، Bash یا هر برنامه دیگری باشد. برای این کار، فقط کافی است فایل متنی تنظیمات crontab را ویرایش کنید و تنظیم کنید که چه چیزی در چه زمانی اجرا شود. تصویر زیر نمونهای از یک کرون جاب را نشان میدهد که در اولین روز هر ماه در ساعت ۳ بامداد اجرا میشود، زمانی که بهروزرسانی انبار دادهها حداقل تأثیر را بر تجربه کاربران دارد. این ابزار ساده است، اما میتوانید از سایتهایی مانند crontab.guru برای ایجاد و تفسیر زمانبندیهای خود استفاده کنید.
مرحله ۲: ETL ماژولار + داکر
پایپلاین بعدی که ساختم برای یک کافیشاپ زنجیرهای بود که داشبورد تجاری برای تجمیع دادههای فروش و مشتریان نیاز داشت. این پروژه چالشهایی داشت؛ برای مثال، کارفرما میخواست یک نسخه پشتیبان از دادههای خام رو هم داشته باشه. بنابراین، تصمیم گرفتیم یک فرآیند ELTL (Extract, Load, Transform, Load) بهجای ETL سنتی طراحی کنیم.
در این پروژه، پردازشهای زیادی روی دادههای حجیم انجام میشد، از جمله محاسبه RFM برای هر مشتری (حدود ۸۰۰۰ مشتری) و تحلیل فروش مشترک محصولان -cross sell- (جدولی با ابعاد ۱۰۰۰×۱۰۰۰). ازآنجاکه این پروژه از پروژه قبلی بزرگتر بود، تصمیم گرفتیم هر مرحله (استخراج، تبدیل و بارگذاری) را به عنوان یک پروژه و سرویس جداگانه نگاه کنیم و همه را داکری کنیم. این کار باعث شد که پروژهها قابل نگهداریتر شوند. اگر دادهها بهروزرسانی نمیشدند، میتوانستیم بهراحتی لاگهای داکر را بررسی کنیم و مشکلات را پیدا کنیم. به عنوان مثال در صورت بروز مشکل در مرحله بارگذاری، مراحل استخراج و تبدیل همچنان بدون وقفه ادامه پیدا کنند.
مرحله ۳: استفاده از Apache Airflow و Avro برای پایپلاین مقیاسپذیر
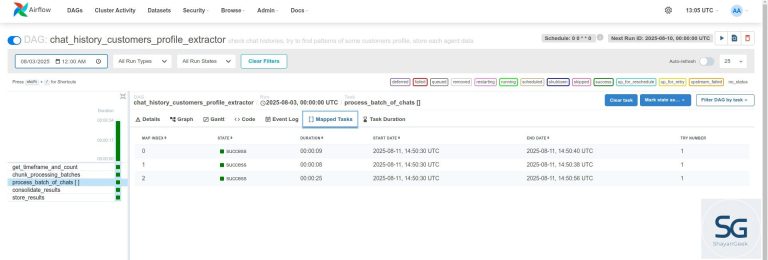
پیچیدهترین پایپلاینی که ساختم، مربوط به یک پروژه داده با مقیاس بالا بود که در آن باید حدود ۱۳ ترابایت داده پردازش میکردیم و هر هفته ۵ گیگابایت به آن اضافه میشد.
چالشهای این پروژه متفاوت بودند. اگرچه هنوز میتوانستم از پروژههای داکریشده برای هر مرحله استخراج، تبدیل و بارگذاری استفاده کنم، اما برخی تفاوتها باعث شد تصمیم بگیرم از Apache Airflow استفاده کنم:
- وابستگیهای پیچیده بین تسکها
- مانیتورینگ و رفع سریعتر خطا
- پروژهای در مقیاس بزرگ که نیاز به تغییرات مداوم داشت (اغلب شامل اضافه کردن قسمتهای جدید)
برای ارکستراسیون فرآیندها از Apache Airflow و برای سریالسازی دادههای بزرگ از Avro استفاده کردم. این کار باعث شد از قابلیتهای بازیابی خودکار و هشدارهای خطا بهرهمند شوم و همچنین یکپارچگی اسکیما را حفظ کنم.
با دادههای حجیم، بهینهسازی اهمیت زیادی پیدا میکند. ما مجبور شدیم تخصیص منابع، کشینگ و اجرای موازی را بهینه کنیم تا زمان پردازش در حد معقول باقی بماند.
نکات کلیدی: آنچه که از پایپلاینهای مقیاسپذیر آموختم
با نگاهی به گذشته، اینها برخی از مهمترین درسهایی هستند که در طول مسیر یاد گرفتم:
- ساده شروع کنید اما برای رشد برنامه داشته باشید – کرون جاب ممکن است برای یک فرآیند کوچک مناسب باشد، اما اگر قصد افزایش مقایس پروژه رو دارید، بهتر است از ابتدا ماژولار طراحی کنید.
- از کانتینرسازی استفاده کنید – داکر، استقرار و مقیاسگذاری را بسیار آسانتر میکند.
- از ابزارهای ارکستراسیون در صورت نیاز استفاده کنید – ابزارهایی مانند Airflow به مدیریت پیچیدگی و تضمین قابلیت اطمینان کمک میکنند ولی شاید برای هر پروژهای مناسب نباشند.
- برای دادههای حجیم بهینهسازی کنید – ابزارهایی مانند Avro، Parquet و Spark میتوانند در پردازش مجموعه دادههای بزرگ تفاوت زیادی ایجاد کنند.
- به مانیتورینگ توجه کنید – لاگها، داشبوردها و سیستمهای هشدار به اجرای بدون نقص پایپلاینهای داده کمک میکنند.
نتیجهگیری
پایپلاینهای داده همراه با رشد کسبوکار تکامل پیدا میکنند. چیزی که بهعنوان یک اسکریپت ساده شروع میشود، میتواند به یک راهکار سازمانی پیچیده با نیاز به ارکستراسیون و مقیاسپذیری تبدیل شود. با ساختاردهی مناسب پایپلاینها و استفاده از ابزارهای مناسب، میتوانید اطمینان حاصل کنید که فرآیندهای دادهای شما بهصورت کارآمد توسعه پیدا میکنند.
اگر شما هم اولین پایپلاین داده خود را ساختهاید یا در حال مقیاسگذاری آن هستید، خوشحال میشوم تجربیات شما را در نظرات بخوانم!