پردازش دستهای در Apache Airflow – تجربهای در عصر کلان داده
حتما تا حالا اسم پردازش دستهای یا batch processing به گوشتون خورده. تو این پست قرار هست در مورد این موضوع و استفاده از اون در Apache Airflow صحبت کنیم.
این روزها با این حجم سرسامآور داده که هر لحظه هم بیشتر میشه، یکی از مهمترین مهارتها اینه که بلد باشیم چطور این کوه داده رو به شکلی کارآمد پردازش کنیم. ابزاری مثل Apache Airflow برای سازماندهی و هماهنگی کارهای پیچیده عالیه، اما وقتی پای دادههای خیلی بزرگ وسط میاد، یه سؤال مهم پیش میاد:
چطور کاری کنیم که ورکرهامون از نفس نیفتن، حافظه منفجر نشه و کارهامون هم بینهایت طول نکشه؟
واقعیت اینه که این موضوع تا قبل از تجربه اخیرم برای اضافه کردن یه ویژگی به محصول شرکتی که دراون مشغول هستم، زیاد برای من هم اهمیتی نداشت. میخواستم با استفاده از یه سرویس NER که همکاران نوشته بودند، متنها رو بررسی کنم و موجودیتهای نام دار معنادار برای کسب و کار رو استخراج کنم. طبق برنامهای که توی ذهنم بود با اجرای روزانه این پروسه، میتونستم بدون مشکل خاصی پردازش رو پیش ببرم؛ اما ماجرا یکم متفاوتتر پیش رفت.
برای شروع لازم بود که پروسه برای تمام چتهای چندماه اخیر انجام بشه که یه حجم عظیمی داده متنی بود. البته بعد از اجرای اول میشد میشد به صورت روزانه صرفا چتهای همون روز رو بررسی کرد که کمتر هستن. اما برای شروع چالش بزرگی داشتم. این موضوع من رو برد سمت پردازش batch در Apache Airflow و با مفهوم Dynamic Task Mapping در این ابزار آشنا شدم. بعد از انجام کار تصمیم گرفتم این تجربه رو باهاتون به اشتراک بذارم. اما قبل از اینکه جلوتر بریم اگه با Apache Airflow آشنا نیستین توصیه میکنم این پست من رو قبلش بخونین.
چرا پردازش دستهای؟ داستان تلخ پردازش “یکباره” دادهها
فرض کنید باید یک میلیون رکورد چت مشتری رو پردازش کنید. شاید وسوسه بشید یه تسک توی Airflow بسازید که کل این یک میلیون رکورد رو یکجا بخونه.
برای داده کم، این شاید جواب بده، ولی برای دادههای بزرگ… فاجعهست!
- پر شدن حافظه: وقتی همه دادهها رو یکجا توی حافظه میریزید، رم پر میشه و تسکتون کرش میکنه.
- تایماوت و دوبارهکاری: تسکهای طولانی ممکنه به خاطر محدودیت زمانی قطع بشن و مجبور بشید از اول شروع کنید.
- عدم استفاده از منابع: یک تسک بزرگ فقط روی یک ورکر اجرا میشه و بقیه منابع بیکار میمونن.
راهحل سادهست: کار رو به «دستههای کوچکتر» تقسیم کنید. مثلاً به جای یک تسک با یک میلیون رکورد، ۱۰۰ تسک بسازید که هر کدوم ۱۰هزار رکورد رو پردازش کنه. اینطوری هم موازیسازی دارید، هم حافظه و زمان کنترلشدهست.
قلب ماجرا: Dynamic Task Mapping
با استفاده از قابلیت نگاشت تسکهای پویا در Airflow شما فقط یه تسک “قالب” تعریف میکنید و Airflow به طور پویا، در زمان اجرا و بر اساس لیستی از ورودیهایی که بهش میدید، نمونههای متعددی از اون تسک رو ایجاد و اجرا میکنه.
تصورش کنید یه کارخونه دارید: شما یه نقشه (تسک partial شما) و یه لیست از مواد خام (ورودیهای expand) بهش میدید، و کارخونه به سرعت و با کارایی بالا، کلی محصول یکسان (نمونههای تسک نگاشت شده) رو تولید میکنه.
بیایید اجزای اصلی این قابلیت رو بررسی کنیم:
.partial(): این متد رو به تعریف یه تسک اضافه میکنیم تا بگیم این یه تسک قابل نگاشت هست. با این کار به Airflow سیگنال میدیم که: “این تسک فقط یه الگوئه؛ پارامترهای کامل اجرای اون به صورت پویا تو زمان اجرا فراهم میشه.” هر آرگومانی که به.partial()میدید، به عنوان آرگومان ثابت برای تمام نمونههای نگاشت شده در نظر گرفته میشه..expand(): این متد روی یه تسک که قبلاً با.partial()مشخص شده، صدا زده میشه و لیست ورودیهایی رو که قراره نگاشت پویا رو هدایت کنه، به Airflow میده. برای هر آیتم تو این لیستی که به.expand()ارسال میکنید، Airflow یه نمونه تسک (task instance) جدید و مجزا (همون “تسک نگاشت شده”) ایجاد میکنه. مقادیری که از لیست میان، به عنوان آرگومان به هر نمونه تسک نگاشت شده پاس داده میشن.
ترکیب هوشمندانه partial() و expand() یه تعریف تسک ساده رو به یه مکانیزم قدرتمند برای پردازش موازی تبدیل میکنه، که کاملاً برای نیازهای دستهبندی ما ایدهآله.
یک مثال کاربردی: بازنویسی برای مقیاسپذیری
بیایید مسالهای که برای من پیش اومد رو با هم بررسی کنیم.
فرض کنید شما قرار هست حجم عظیمی از دادهها رو پردازش کنین. ممکنه این دادهها صرفا برای اولین بار زیاد باشن یا اینکه با گذشت زمان و زیاد شدن دادههای روزانه و حتی ساعتی این چالش براتون پیش بیاد.
یه DAG که خوب بهینهسازی نشده باشه، ممکنه یه تسک واحد داشته باشه که همه چتها رو یکجا واکشی کنه و اینجا یه گلوگاه ایجاد بشه. حالا، نسخهای که با هم بازنویسی میکنیم، یه پایپلاین قوی و مقیاسپذیر با استفاده از Dynamic Task Mapping رو نشون میده.
۱. تعیین گستره کار: get_timeframe_and_count
اولین قدم خیلی مهم اینه که گستره دادههامون رو بفهمیم، اونم بدون اینکه کل دادهها رو تو حافظه بارگذاری کنیم. این تسک، تعداد کل رکوردها رو برای یه بازه زمانی مشخص پیدا میکنه. در این مثال فرض کردم دارم دیتای رو از یک کالکشن MongoDB به اسم data_collection میخونم.
from airflow.decorators import task
@task
def get_timeframe_and_count(**context):
start_time = "2025-01-01T00:00:00Z"
end_time = "2025-01-02T00:00:00Z"
# This task now ONLY gets the count of documents, not the documents themselves.
# This is a lightweight database operation.
chat_count = data_collection.count_documents({
"created_at": {
"$gte": start_time,
"$lt": end_time,
}
})
print(f"Total chats to process: {chat_count}")
return {"start_time": start_time, "end_time": end_time, "chat_count": chat_count}
این تسک طوری طراحی شده که سبک و سریع باشه. اون اطلاعات ضروری (تعداد کل، محدودههای زمانی) رو که برای استراتژی دستهبندیمون لازم داریم، بدون مصرف بیش از حد منابع، بهمون میده.
در این تسک من تاریخ شروع و پایان رو ثابت گرفتم توی کد واقعی ممکنه زمانهای نسبی (مثل دیروز، یک ساعت پیش و..) یا زمان آخرین اجرای موفق این تسک رو گرفته باشین. من خودم از روش دوم استفاده کردم ولی اینجا کدش رو نمیذارم که از بحث اصلی خارج نشیم.
۲. آمادهسازی دستهها: chunk_processing_batches
حالا باید یه لیست از دیکشنریهای batch درست کنیم. هر دیکشنری شامل پارامترهای لازم (مثل skip و limit برای یک کوئری دیتابیس) برای یه ورکر هست تا یه زیرمجموعه خاص از دادهها رو پردازش کنه. این لیست، ورودی اصلی برای Dynamic Task Mapping ما خواهد بود.
برای محاسبه تعداد batchها هم سعی کردم با یک کار ساده یه ceiling division انجام بدم :))
@task
def chunk_processing_batches(timeframe_and_count: dict):
batch_size = 1000
total_count = timeframe_and_count["chat_count"]
start_time = timeframe_and_count["start_time"]
end_time = timeframe_and_count["end_time"]
num_batches = (total_count + batch_size - 1) // batch_size
batches = []
for i in range(num_batches):
skip = i * batch_size
batches.append({
"skip": skip,
"limit": batch_size,
"start_time": start_time,
"end_time": end_time
})
print(f"Generated {len(batches)} batches.")
return batches
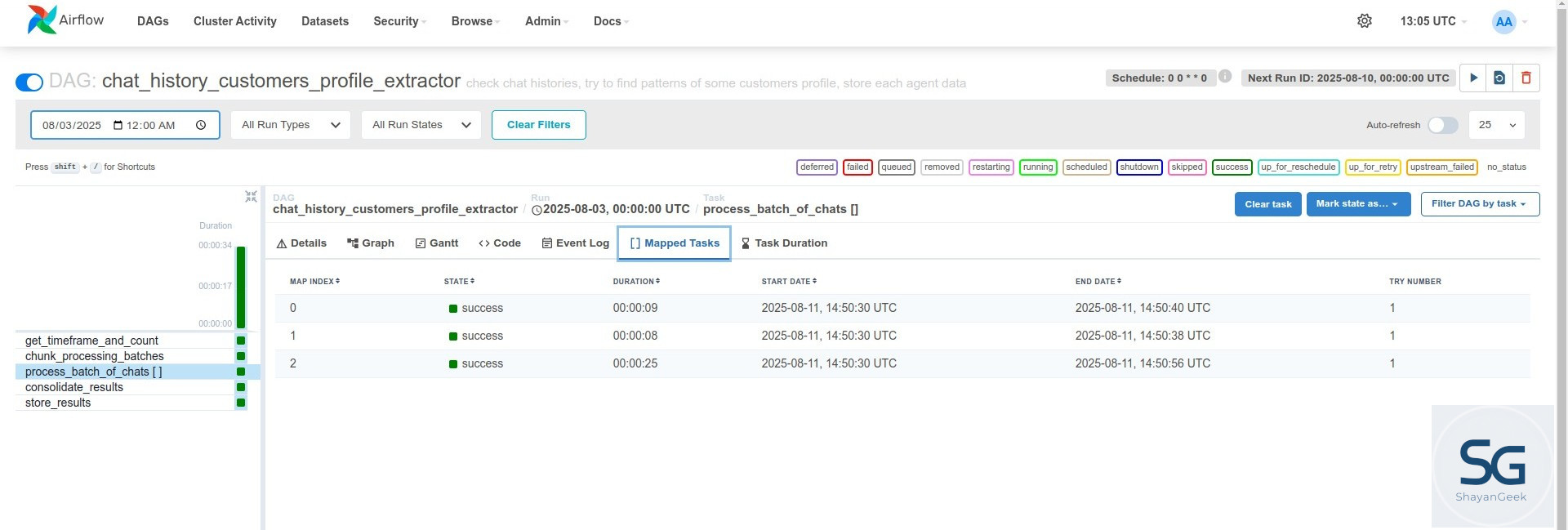
۳. پردازش موازی: process_batch_of_chats
حالا میرسیم به اصل ماجرا، یعنی منطق پردازش اصلی. ما تسکی رو تعریف میکنیم که یه دسته واحد رو مدیریت میکنه، و بعد با استفاده از Dynamic Task Mapping، اون رو به صورت موازی برای همه دستههایی که ساختیم اجرا میکنیم.
@task(pool="extract_pool")
def process_batch_of_chats(batch_info: dict):
skip = batch_info["skip"]
limit = batch_info["limit"]
start_time = batch_info["start_time"]
end_time = batch_info["end_time"]
print(f"Processing batch: skip={skip}, limit={limit}")
# This task now performs a LIMITED query on the database, fetching only its batch.
chat_sessions = data_collection.find(
{ "created_at": { "$gte": start_time, "$lt": end_time } }
).skip(skip).limit(limit)
entities_batch = []
for chat_session in chat_sessions:
# ... complex logic to extract entities, analyze sentiment, etc. ...
# Example: just appending a placeholder for demonstration
entities_batch.append(f"Processed_Chat_{chat_session.get('_id', 'N/A')}")
print(f"Finished batch: {len(entities_batch)} items processed.")
return entities_batch
در نهایت هم DAG رو تعریف میکنیم.
from airflow.models.dag import DAG
from datetime import datetime
with DAG(
dag_id="scalable_batch_processing_example",
start_date=datetime(2025, 01, 01),
schedule=None,
catchup=False,
tags=["batch", "dynamic_mapping", "tutorial"],
) as dag:
timeframe = get_timeframe_and_count()
batches = chunk_processing_batches(timeframe)
results = process_batch_of_chats.partial().expand(batch_info=batches)
با صدا زدن .partial().expand()، ما عملاً به Airflow دستور دادیم که چندین نمونه از process_batch_of_chats رو راهاندازی کنه، که هر کدومشون یه دیکشنری batch_info منحصر به فرد دریافت میکنن. این دقیقاً همون چیزیه که قدرت پردازش موازی ورکرهای Airflow رو مورد استفاده قرار میده.
جمعبندی: قدرتمند کردن پایپلاینهای شما با پردازش دستهای
پردازش دستهای، که با قابلیت Dynamic Task Mapping در Airflow تقویت میشه، یه الگوی ضروری برای ساخت پایپلاینهای دادهای مقیاسپذیر، مقاوم و کارآمد هست. این روش به طور مستقیم با چالشهای رایجی مثل محدودیتهای حافظه و تسکهای طولانیمدت مقابله میکنه و به شما اجازه میده دادههای واقعاً عظیم رو بدون به خطر انداختن عملکرد یا پایداری، پردازش کنید. توصیه میکنم برای درک بهتر موضوع پردازش دستهای و البته ویژگیهای دیگه Apache Airflow حتما داکیومنتهای رسمی مثل این صفحه رو بخونین.