Batch Processing in Apache Airflow
You’ve probably heard the term batch processing before.
In this post, we’ll talk about what it means and how to use it in Apache Airflow.
These days, with the mind-boggling amount of data growing by the second, one of the most important skills you can have is knowing how to process massive datasets efficiently. Tools like Apache Airflow are fantastic for organizing and coordinating complex workflows, but when you’re dealing with huge amounts of data, one big question comes up:
How do we keep our workers from burning out, our memory from exploding, and our tasks from running forever?
Honestly, I never thought much about this until a recent experience while adding a new feature to my company’s product.
The plan was to use an in-house NER service (built by my teammates) to analyze text and extract named entities relevant to our business. My idea was simple: run this process daily without much trouble.
But things turned out differently.
For the first run, I needed to process months of past chat history — a massive pile of text data. Sure, after that, I could process only new daily chats, but the initial run was going to be a big challenge.
That’s when I started looking into batch processing in Apache Airflow and discovered Dynamic Task Mapping. After I got it working, I thought, I should share this experience with you.
If you’re not familiar with Apache Airflow, I suggest checking out my earlier post on it before continuing.
Why Batch Processing? The Problem with “One-Shot” Data Processing
Imagine you need to process one million customer chat records.
You might be tempted to create one Airflow task that loads and processes all one million records at once.
For small datasets, this might work. But with large data… it’s a disaster:
- Memory overload – Loading everything into memory at once will fill up your RAM and crash your task.
- Timeouts and retries – Long-running tasks can hit time limits and force you to start over.
- Poor resource usage – One giant task runs on a single worker, leaving other workers idle.
The solution is simple: split the work into smaller batches.
For example, instead of one task processing 1,000,000 records, create 100 tasks that each process 10,000. This gives you:
- Parallel processing
- Controlled memory usage
- Faster overall execution
The Heart of It: Dynamic Task Mapping
Dynamic Task Mapping in Airflow lets you define a template task that Airflow can clone at runtime based on a list of inputs.
Think of it like a factory:
You give it a blueprint (your template task) and a list of raw materials (your input list), and the factory produces many identical products (mapped tasks) quickly and efficiently.
The main building blocks are:
.partial()– Marks your task as a template and sets fixed arguments for all mapped tasks..expand()– Provides the list of inputs, creating one mapped task per input.
By combining .partial() and .expand(), you turn a simple task definition into a parallel processing engine—perfect for batch processing.
A Practical Example – Rewriting for Scalability
Here’s the scenario:
We need to process a huge dataset. Maybe it’s only huge the first time, or maybe it grows daily or even hourly. Either way, a single “fetch-all” task will quickly become a bottleneck.
Instead, let’s rewrite it into a scalable, parallelized pipeline using Dynamic Task Mapping.
1. Define the workload – get_timeframe_and_count
We first figure out how many records we need to process for a given time range—without actually loading them all into memory.
from airflow.decorators import task
@task
def get_timeframe_and_count(**context):
start_time = "2025-01-01T00:00:00Z"
end_time = "2025-01-02T00:00:00Z"
# This task now ONLY gets the count of documents, not the documents themselves.
# This is a lightweight database operation.
chat_count = data_collection.count_documents({
"created_at": {
"$gte": start_time,
"$lt": end_time,
}
})
print(f"Total chats to process: {chat_count}")
return {"start_time": start_time, "end_time": end_time, "chat_count": chat_count}
This is a lightweight task—fast, memory-friendly, and giving us exactly what we need to plan our batches.
2. Create the batches – chunk_processing_batches
Now we split the work into manageable chunks for our workers.
@task
def chunk_processing_batches(timeframe_and_count: dict):
batch_size = 1000
total_count = timeframe_and_count["chat_count"]
start_time = timeframe_and_count["start_time"]
end_time = timeframe_and_count["end_time"]
num_batches = (total_count + batch_size - 1) // batch_size
batches = []
for i in range(num_batches):
skip = i * batch_size
batches.append({
"skip": skip,
"limit": batch_size,
"start_time": start_time,
"end_time": end_time
})
print(f"Generated {len(batches)} batches.")
return batches
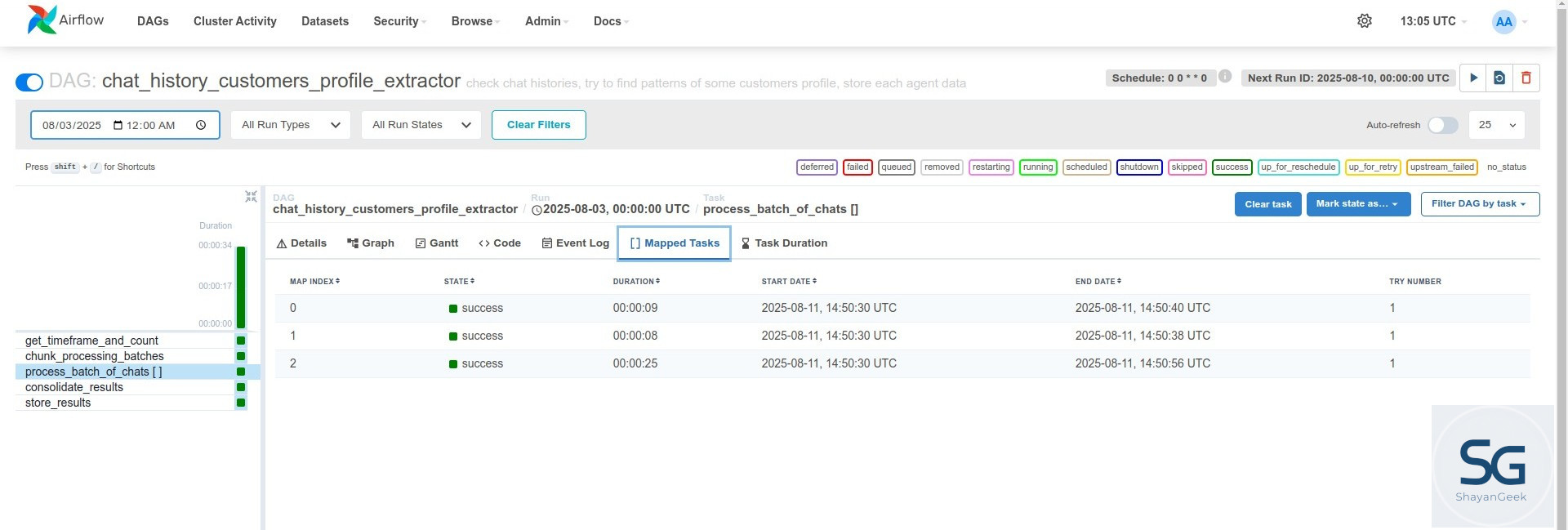
3. Process each batch in parallel – process_batch_of_chats
This is the actual processing logic—now running on one batch at a time.
@task(pool="extract_pool")
def process_batch_of_chats(batch_info: dict):
skip = batch_info["skip"]
limit = batch_info["limit"]
start_time = batch_info["start_time"]
end_time = batch_info["end_time"]
print(f"Processing batch: skip={skip}, limit={limit}")
# This task now performs a LIMITED query on the database, fetching only its batch.
chat_sessions = data_collection.find(
{ "created_at": { "$gte": start_time, "$lt": end_time } }
).skip(skip).limit(limit)
entities_batch = []
for chat_session in chat_sessions:
# ... complex logic to extract entities, analyze sentiment, etc. ...
# Example: just appending a placeholder for demonstration
entities_batch.append(f"Processed_Chat_{chat_session.get('_id', 'N/A')}")
print(f"Finished batch: {len(entities_batch)} items processed.")
return entities_batch
4. Put it all together – The DAG
from airflow.models.dag import DAG
from datetime import datetime
with DAG(
dag_id="scalable_batch_processing_example",
start_date=datetime(2025, 01, 01),
schedule=None,
catchup=False,
tags=["batch", "dynamic_mapping", "tutorial"],
) as dag:
timeframe = get_timeframe_and_count()
batches = chunk_processing_batches(timeframe)
results = process_batch_of_chats.partial().expand(batch_info=batches)
With .partial().expand(), we tell Airflow to spawn multiple parallel tasks, each handling a different subset of the data—maximizing our worker utilization and speeding things up.
Takeaways – Supercharging Your Pipelines with Batch Processing
Batch processing, powered by Dynamic Task Mapping, is a must-have pattern for building scalable, reliable, and efficient data pipelines.
It tackles common challenges like memory limits and long-running tasks head-on, letting you process truly massive datasets without sacrificing performance or stability.
If you want to explore further, I highly recommend checking Airflow’s official documentation—especially the section on Dynamic Task Mapping.