How to Build Scalable Data Pipelines: A Beginner’s Guide
From Simple Scripts to Enterprise-Grade Pipelines: My Data Engineering Journey
Building data pipelines is an evolving craft. It’s not just about moving data from one place to another—it’s about ensuring reliability, scalability, and efficiency at every stage. My journey started with simple Python scripts for a travel agency and led me to architect robust pipelines for large-scale projects. In this post, I’ll take you through that journey, demonstrating how data pipelines evolve as business needs grow.
If you’re new to data engineering or looking to improve your pipelines, this guide will walk you through the process—from the basics to advanced implementations.
(For a broader look at essential data engineering tools, check out my previous blog post: Essential Tools for Data Engineering.)
Stage 1: The Humble Beginnings – Python Scripts and Cron Jobs
When I first started working on data pipelines, the requirements were simple. I was tasked with automating a small data process for a travel agency.
They needed to collect ticket sales data from an API and store it in a relational database for reporting and business intelligence purposes.
The solution was simple. I wrote a Python script that:
- Pulled data from APIs using
requests - Cleaned and transformed the data using
pandas. - Inserted the structured data into a PostgreSQL database.
- Used
cronjobs to schedule the script to run every few hours.
The solution was straightforward. I wrote a Python script that:
- Pulled data from APIs using
requests. - Cleaned and transformed the data using
pandas. - Inserted the structured data into a PostgreSQL database.
- Used cron jobs to schedule the script to run every few hours.
At the beginning, I evaluated the scale of the problem. Given its simplicity and small scope, I preferred using a cron job in Linux. This simple tool allows you to schedule tasks at specified intervals, regardless of whether they are Python scripts, Bash commands, or other applications.
To set up a cron job, you just need to edit a configuration file and define the execution schedule. For example, the following cron job runs on the first day of each month at 03:00 AM, which is a good time for updating data warehouses with minimal impact on end-user experience:
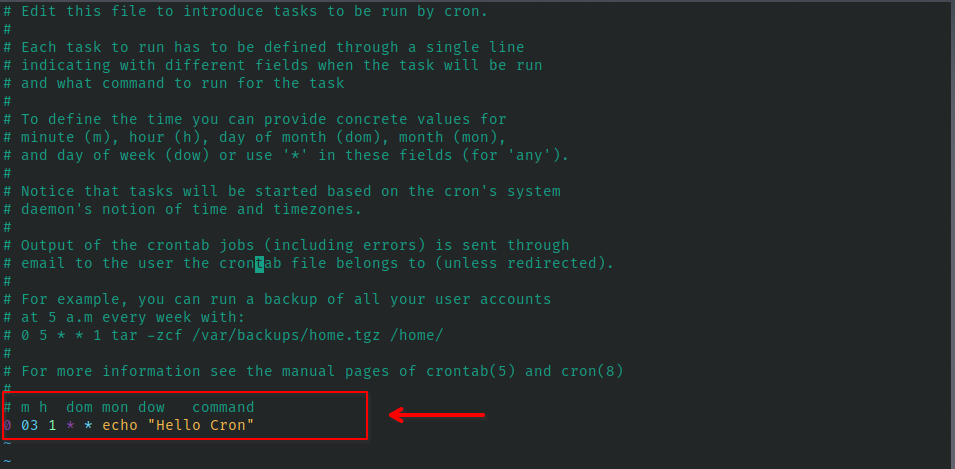
To simplify cron job scheduling, you can use websites like crontab.guru to generate and interpret cron expressions.
Stage 2: Modular ETL with Dockerized Services
The next major pipeline I built was for a café chain that wanted a business dashboard for sales and customer data.
Challenges:
- The stakeholders required both dashboards and a backup of raw data.
- The project involved complex calculations on large datasets.
- We needed scalability and maintainability.
To address these challenges, we designed an ELTL (Extract, Load, Transform, Load) pipeline instead of a traditional ETL. This approach allowed us to store raw data before transformation for auditing and reprocessing if needed.
For example, we implemented:
- RFM analysis for each of ~8,000 customers.
- Cross-sell recommendations, resulting in a 1,000×1,000 matrix.
Since this project was larger than the previous one, we adopted a modular approach:
- Each step (Extract, Transform, Load) was developed as a separate repository.
- We containerized each module using Docker.
Benefits of Dockerization:
- Improved maintainability – Each service was independent, making debugging easier.
- Fault isolation – If one component failed (e.g., loading), extraction and transformation could still function.
- Easy debugging – Checking Docker logs helped quickly identify issues without affecting the entire system.
Stage 3: Scaling Up with Apache Airflow and Avro
The most complex pipeline I built was for a high-scale data project, processing 13TB of data, with 5GB added weekly.
Challenges:
- Complex dependencies between tasks.
- Need for fault tolerance and monitoring.
- Frequent changes and new components requiring future-proofing.
While I could have continued using separate Dockerized projects, I decided to adopt Apache Airflow for workflow orchestration because it provided:
- Task dependencies management – Ensuring correct execution order.
- Retries and alerting – Automatically handling failures.
- Scalability – Supporting future pipeline expansions.
Additionally, I used Avro for data serialization to optimize storage and ensure schema evolution.
Optimization strategies:
Parallel execution to improve efficiency.
Fine-tuning resource allocation to optimize performance.
Caching intermediate results to avoid redundant processing.
Key Takeaways: What I Learned About Scalable Pipelines
Reflecting on my journey, here are the core lessons I learned:
- Start simple but plan for growth – A cron job might work for a small process, but early modularization helps future scalability.
- Use containerization – Docker simplifies deployment and scaling.
- Embrace workflow orchestration – Tools like Apache Airflow streamline task dependencies and reliability.
- Optimize for big data – Technologies like Avro, Parquet, and Spark significantly enhance performance.
- Prioritize monitoring and alerting – Logging, dashboards, and alerts ensure smooth pipeline operation.
Final Thoughts
Data pipelines grow alongside business needs. What starts as a simple script can evolve into an enterprise-grade system requiring orchestration, fault tolerance, and scalability.
By structuring pipelines properly and adopting the right tools, you can ensure that your data processes remain efficient and resilient as they evolve.
If you’re building your first data pipeline or looking to scale an existing one, I’d love to hear your thoughts and experiences in the comments!
(Don’t forget to check out my post on Essential Tools for Data Engineering for more insights!)