The Data Engineer’s Dilemma: Batch, Stream, or Hybrid?
There’s a moment in every data engineer’s journey when the excitement of building pipelines meets a difficult, quiet question:
Should this run in batch, or should it be real-time?
It sounds technical — but it’s actually philosophical. Behind it lies a deeper question:
What are we really optimizing for — freshness, simplicity, or reliability?
Because you can’t have all three.
Let’s unpack this dilemma — not by talking about tools, but by exploring the conceptual forces that shape every data system.
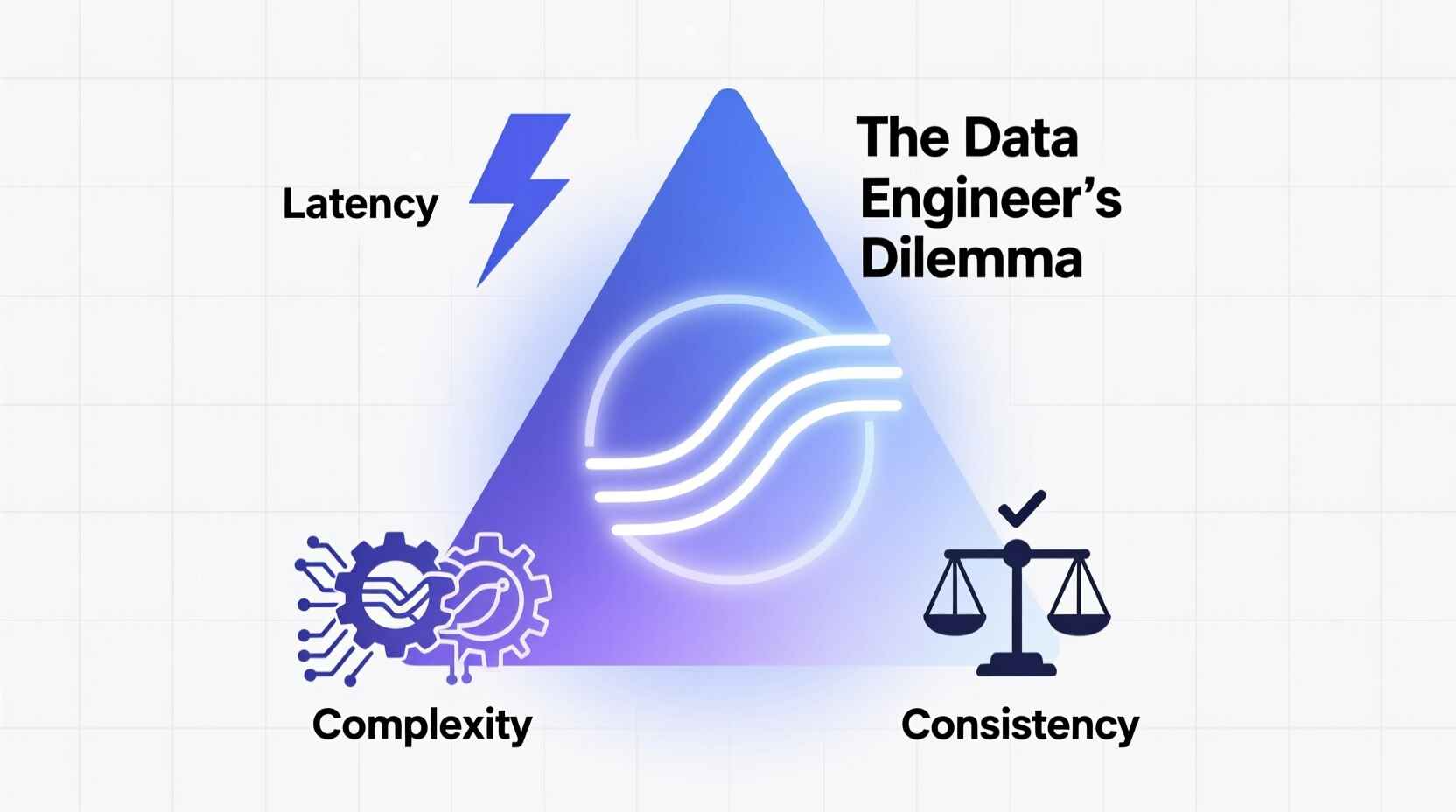
1. The Three Forces Behind Every Data Decision
Every data pipeline lives in a space defined by three competing values:
Latency — How fast the data becomes available.
Complexity — How hard it is to build and maintain.
Consistency — How correct and replayable the results are.
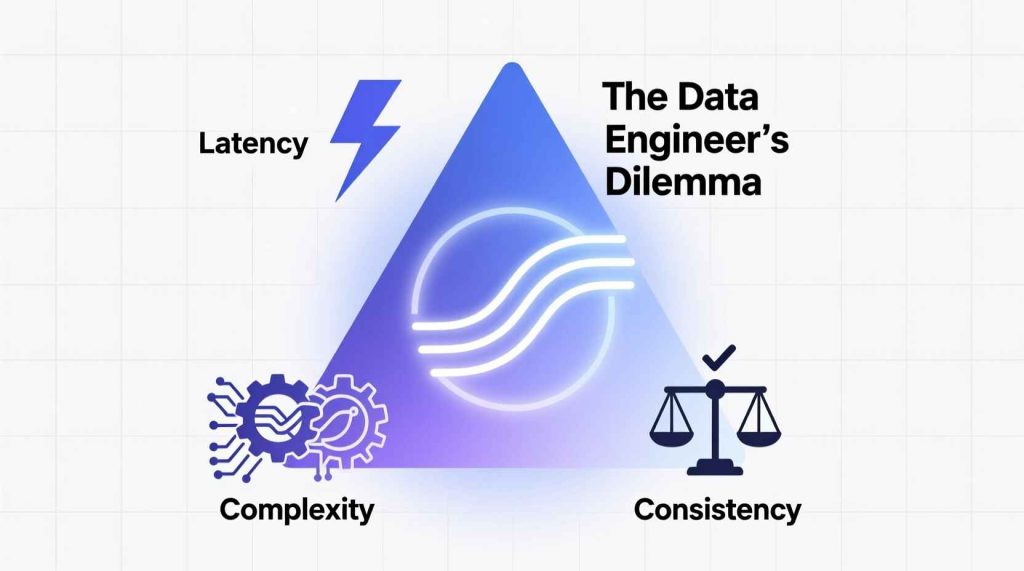
You can pick two, but the third always costs you.
If you go for low latency and consistency, you’ll pay with complexity.
If you choose simplicity and correctness, you’ll sacrifice speed.
This is the real “data engineer’s dilemma.”
The challenge isn’t picking the best technology — it’s choosing which pain you can live with.
2. Batch, Stream, and the Middle Ground
Forget the tools for a second. Think about how data behaves.
Batch
Batch processing assumes the world can pause.
You wait for data to arrive, take a snapshot, process it, and produce results that are complete and auditable.
It’s like publishing a newspaper every morning — what’s written is final until tomorrow.
Batch pipelines are easier to reason about because time has boundaries.
They fail loudly, they can be rerun, and they produce stable outputs.
But they will always be one step behind reality.
Stream
Streaming assumes the world never stops.
Data flows continuously, and you process it as it arrives — no waiting for completeness.
It’s like watching live news: you get updates instantly, but facts may change later.
The advantage is freshness, but the cost is uncertainty.
In streaming, you must deal with late events, evolving state, and moving truth.
You can’t just rerun; you must be ready to handle time itself.
Hybrid
Hybrid systems try to get the best of both.
They serve real-time updates quickly and later reconcile or reprocess for accuracy.
It’s like having a live news ticker that gets rewritten into a verified article at night.
This idea — sometimes called convergent pipelines — accepts that data starts noisy but stabilizes over time.
It’s a mature compromise: fast first, correct later.
3. The Dimensions of Trade-Offs
When deciding between batch, stream, and hybrid, it helps to look beyond “speed.”
Here are the deeper dimensions that matter.
Latency vs. Consistency
Batch pipelines guarantee completeness — you know exactly which data was included.
Streaming systems, on the other hand, deal with partial truth — data may arrive late, out of order, or twice.
A good rule of thumb:
If your downstream logic depends on a final, immutable view of time, batch is your friend.
If you can live with incremental truth, go streaming.
Complexity vs. Maintainability
Streaming systems can become conceptually tangled because time never stops.
You need checkpointing, state management, event-time handling, and more.
Batch systems, in contrast, are self-contained — each run is a clean slate.
State and Reprocessing
In batch, the data is the state.
In stream, you must explicitly maintain state — what you’ve seen so far, aggregated results, etc.
Here’s a conceptual Python example that shows the difference:
# Batch
data = load_file("sales_2025_10_28.csv")
total_sales = data.groupby("region")["amount"].sum()
store(total_sales, "daily_summary.csv")
# Stream
state = defaultdict(float)
for event in consume_stream("sales_topic"):
state[event["region"]] += event["amount"]
if should_emit_update():
emit("sales_live_summary", dict(state))
In batch, the result is final — a clean snapshot.
In stream, you maintain continuity — the story never ends.
4. Time as a Spectrum, Not a Switch
We often talk about batch vs. streaming as a binary choice.
But in reality, timeliness is a spectrum.
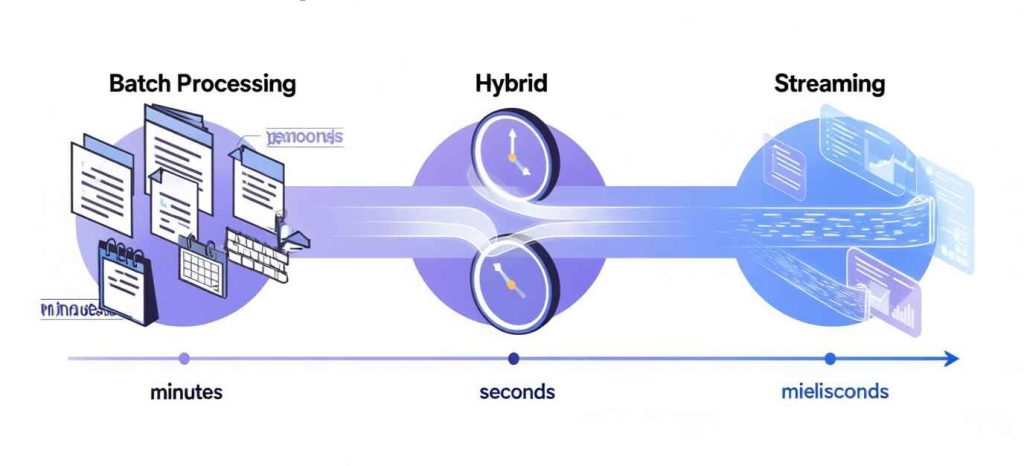
Some systems only need weekly aggregation; others need updates every minute or second.
It’s not about being “real-time” — it’s about being right-time.
Ask yourself:
- How long can your consumer wait before data becomes useless?
- What is the cost of stale data vs. the cost of operational complexity?
Sometimes, refreshing every hour feels “real-time enough.”
And that’s completely fine.
5. A Framework for Choosing
Let’s simplify the thought process. Before deciding architecture, think about these five conceptual questions:
- Nature of Events — Are they discrete (like transactions) or continuous (like sensor streams)?
- Tolerance for Staleness — How quickly must the insight be available?
- Error Correction — Will you need to rewrite history or fix past records?
- Operational Capacity — Can your team handle 24/7 systems and incident response?
- Lifecycle of Truth — Does data stabilize after a while, or is it always evolving?
Most of the time, the answer points toward hybrid — fast layers for quick visibility, slow layers for truth.
6. Convergent Pipelines: Where the Future Lies
Modern systems increasingly combine both worlds.
They process events in near-real-time, emit quick insights, and later backfill to ensure correctness.
This approach aligns beautifully with the nature of business reality — information matures.
Data that’s “good enough” for monitoring today becomes “final truth” tomorrow.
Conceptually, you can think of this as:
- Immediate layer: approximate, fresh.
- Correction layer: verified, consistent.
- Historical layer: immutable, optimized for analytics.
The result is a system that evolves over time, just like knowledge itself.
7. Beyond Technology: The Human Side
The choice between batch and stream isn’t just technical.
It’s about team design, culture, and priorities.
Batch systems work well for teams that value control, auditing, and simplicity.
Streaming systems require operational maturity and a mindset that embraces continuous change.
Hybrid systems need strong communication between data, infrastructure, and business teams — because truth becomes a process, not a product.
In other words, your architecture will reflect what your organization truly values.
Final Thought
In the end, there is no universal answer.
Every data pipeline tells a story about its builders — what they cared about, what they feared, and what they were willing to trade.
Batch, stream, or hybrid isn’t a technical identity.
It’s a design philosophy.
And the best engineers aren’t the ones who pick the “right” one — they’re the ones who understand why their choice makes sense.