الستیک سرچ – بخش اول: کوئریها و فیلترها
وقتی برای اولین بار با الستیکسرچ (Elasticsearch) آشنا شدم، با خودم گفتم: «خب، اینم یه پایگاه دادهی دیگه… درسته؟» اما اشتباه میکردم. الستیکسرچ واقعاً فرق داره. یه جورایی حس ترکیبی از یک موتور جستوجو و یه پایگاه داده رو میده. راستش رو بخواین خودمم هنوز خیلی باهاش راحت نیستم 🙂 اما تو این پست که بخش اول از یک مجموعهس قراره بگم که تا الآن چطوری از کوئریهای الستیکسرچ تو پروژهها استفاده کردم. ضمنا یه جورایی مثل یادداشتهایی برای خودم در آینده است (و امیدوارم برای تو هم مفید باشه).
مدل داده
در هستهی اصلیش، الستیکسرچ روی یک ساختار سلسلهمراتبی ساده ساخته شده:
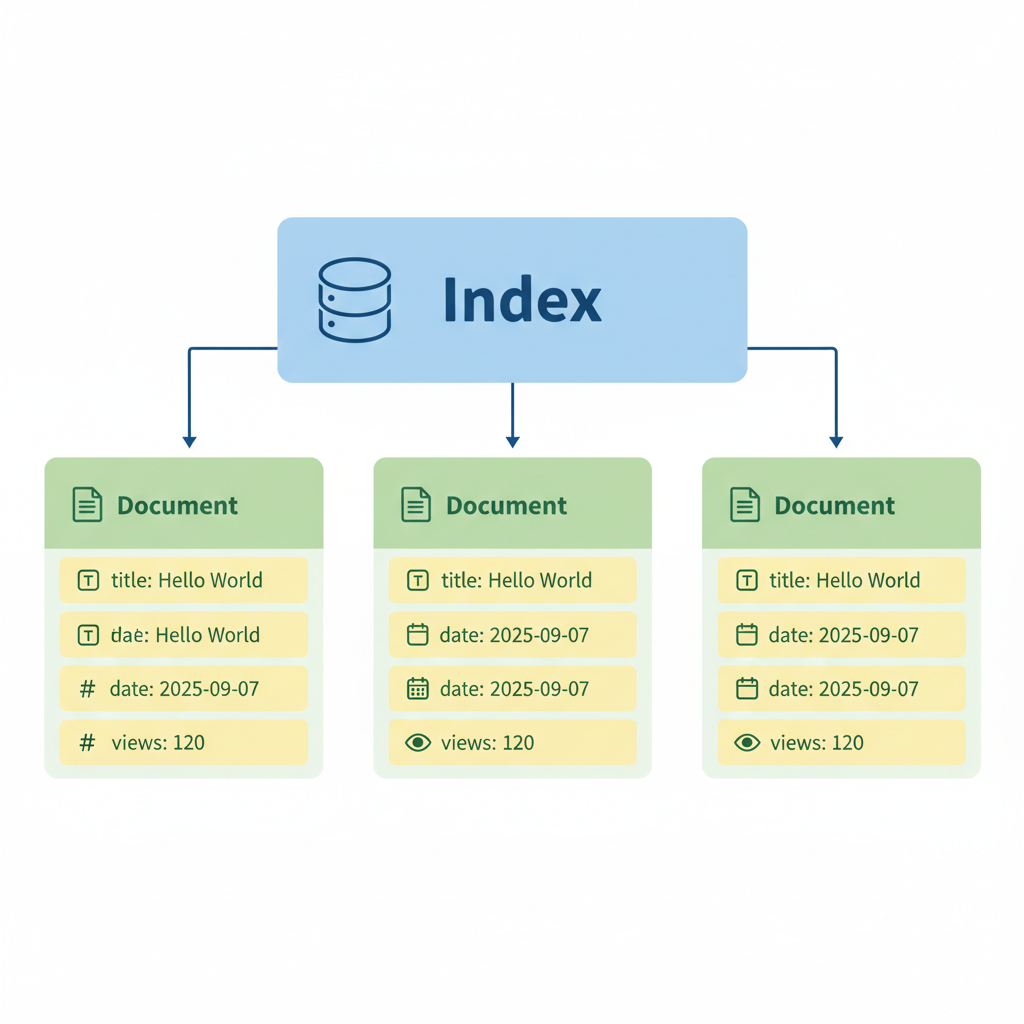
اگر با SQL کار کردی، ایندکس (Index) رو مثل یک جدول (Table)، داکیومنت (Document) رو مثل یک ردیف (Row)، و فیلد (Field) رو مثل یک ستون (Column) در نظر بگیر. اما یه پیچش جالب داره: الستیکسرچ انعطافپذیرتره. نیازی نیست از قبل هر ستون رو با یک شمای سختگیرانه تعریف کنی. با خوشحالی داکیومنتهای JSON رو به صورت لحظهای قبول میکنه. با این حال، مَپینگ (Mapping) خیلی مهمه.
چرا مپینگ؟
الستیکسرچ اگر بهش نگی، با کمال میل «نوع» فیلدهات رو حدس میزنه. گاهی اوقات درست حدس میزنه. گاهی هم نه. مثال: شاید فکر کنی order_id یک عدد هست، ولی ES ممکنه اون رو به عنوان متن ذخیره کنه. همین اشتباه کوچیک بعداً وقتی بخوای بر اساس اون مرتبسازی کنی یا فیلترهای عددی بزنی، حسابی اذیتت میکنه. قاعدهی کلی: همیشه برای فیلدهای مهم مپینگ رو تعریف کن. مثل این میمونه که قبل از ساختن خونه، پیریزی رو درست انجام بدی.
کوئری در برابر فیلتر
اینجا جاییه که خیلی از تازهکارها (از جمله منِ چند وقت پیش) گیج میشن.
کانتکست کوئری (Query context) مربوط به ارتباط (Relevance) هست. ES یک امتیاز بهش میده: «این داکیومنت از اون یکی بهتر مطابقت داره.» برای باکسهای جستوجو، جستوجوی محصولات، یا هر چیزی که نیاز به رتبهبندی نتایج داره، عالیه. کانتکست فیلتر (Filter context) مربوط به محدودیتها (Constraints) هست. تو میخوای دقیقاً مطابقت داشته باشه یا در یک بازه خاصی باشه، و امتیازدهی برات مهم نیست. فیلترها فوقالعاده سریع هستن چون میتونن کش (cache) بشن. اینجوری فکر کن:
کوئری = «کدوم کتابها به کسی که ‘هری پاتر’ رو تایپ کرده، بیشتر مرتبطه؟»
فیلتر = «فقط کتابهایی رو نشون بده که موجودی دارن و قیمتشون کمتر از ۲۰ دلاره.»
چه زمانی از فیلتر استفاده کنیم و چه زمانی از مچ (Match)
من به عنوان یه قاعده کلی میتونم بگم اینطوری تصمیم میگیرم: اگه کسی چیزی رو تو نوار جستوجو تایپ میکنه از match (کانتکست کوئری) استفاده کن، ولی اگه داری دادهها رو توی یک داشبورد برش میزنی و دستهبندی میکنی یا قوانین کسبوکار رو اعمال میکنی از فیلترها استفاده کن.
مثال ۱ – جستوجوی متن
GET orders/_search
{
"query": {
"match": {"customer": "sara"}
}
}
این، دنبال داکیومنتهایی میگرده که فیلد customer شبیه «sara» باشه. این جستوجو دقیق نیست: «Sara»، «Sarah» یا حتی «saraa» رو هم پیدا میکنه. این به این دلیله که ES متن رو توکِنسازی (tokenize) و تحلیل (analyze) میکنه. برای وقتی که آدمها ورودیهای نامرتب تایپ میکنن، عالیه.
مثال ۲ – فیلترهای دقیق
GET orders/_search
{
"query": {
"bool": {
"filter": [
{"term": {"status": "paid"}},
{"range": {"total": {"gte": 100}}}
]
}
}
}
این دقیقا شبیه به WHERE status = 'paid' AND total >= 100 در SQL هست. امتیازی وجود نداره، هیچ گونه گنگی و ابهامی در کار نیست. فقط محدودیتهای خالص. من از این روش برای گزارشها، داشبوردها یا کارهای پسزمینه استفاده میکنم که ارتباط (relevance) دادهها مهم نیست و فقط خود دادهها رو نیاز دارم.
مثال ۳ – ترکیب هر دو
و اینجاست که الستیکسرچ واقعاً میدرخشه: مجبور نیستی یکی رو انتخاب کنی. میتونی هر دو رو با هم ترکیب کنی.
GET orders/_search
{
"query": {
"bool": {
"must": {"match": {"customer": "sara"}},
"filter": {"term": {"status": "paid"}}
}
}
}
این کوئری میگه: «همهی سفارشهای ‘سارا’ رو پیدا کن، اما فقط اونهایی رو که پرداخت شدن.» match مطمئن میشه که ما انواع مختلف «سارا» رو پوشش میدیم (با امتیازدهی بر اساس ارتباط)، در حالی که filter مطمئن میشه که وقتمون رو برای سفارشهای پرداخت نشده هدر نمیدیم.
استفاده از Bool
بیشتر کوئریهایی که من در محیطهای عملیاتی مینویسم، یک match یا یک filter ساده نیستن. اونا یک کوئری bool هستن— ترکیبی از شرایطی که با هم اون چیزی رو که من میخوام شکل میدن.
must: چیزهایی که روی امتیازدهی تأثیر میذارن (مثلmatch)filter: محدودیتهای ارزون و سریعی که امتیازدهی براشون مهم نیستmust_not: حذف داکیومنتهای خاصshould: اگر چیزی مطابقت داشت، امتیاز اضافی بهش بده
وقتی شروع به استفاده از bool میکنی، الستیکسرچ دیگه جادویی به نظر نمیرسه و منطقی میشه.
جمعبندی
پس تو این قدم اول، اینا رو یاد گرفتیم:
- الستیکسرچ چطور به دادهها نگاه میکنه (ایندکس – داکیومنت – فیلد)
- چرا مپینگ مهمه
- تفاوت بین کوئری (امتیازدهی) و فیلتر (محدودیتها)
- چطور با
boolهر دو رو با هم ترکیب کنیم
اگه این مثالها رو توی کلستر خودت اجرا کنی، همین حالا هم قدرت ES رو میبینی. تو بخش بعدی، عمیقتر وارد تحلیل متن میشیم: چطور ES توکِنسازی میکنه، آنالایزرها چی هستن، و چرا جستوجو برای «quick fox» ممکنه «the quickest fox» رو هم پیدا کنه.